Details
Description
Since this topic is nearly as old as XenServer itself and noone cared about it until now, I declared it as a big bug, because it's impacts are from annoying time-waste to broken backups/backup windows.
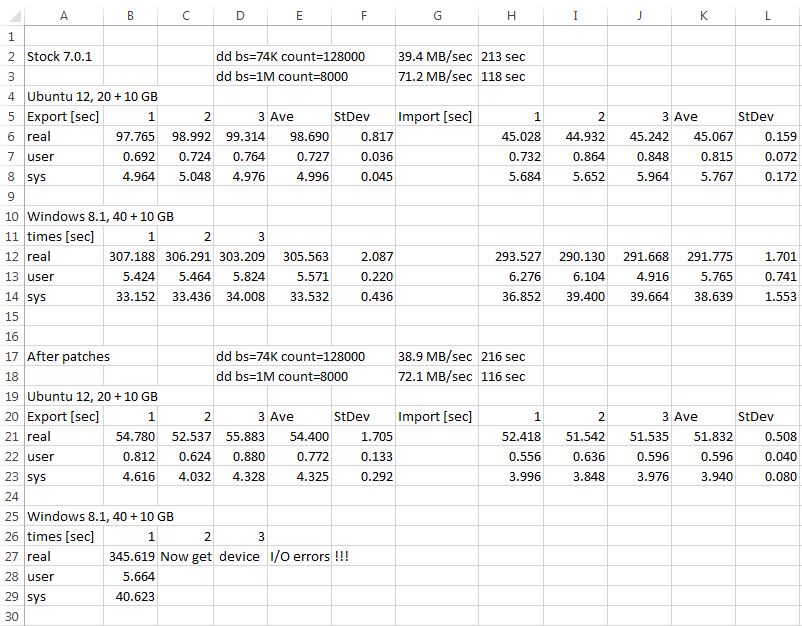
We have an MS Exchange 2007 VM with a database of about 400 GB + OS etc. and usually export the whole VM once a month to have a disaster recovery, which could be imported on any XenServer, if something really bad happens.
The export-process now takes ridiculous 12+ (twelve!) hours.
The environment details are as following:
XenServer 6.5 SP1 (upgraded since about 6.0)
2x Xeon E5-2690 (2.9-3.8 GHz octacore)
128 GB RAM
7x 600 GB 2.5" 10k SAS via P420i/2 GB as LVM, local storage repo
Dom0 set to 4 GB (tested with 3 GB before, will see if it makes a difference, which I don't expect)
Backupserver:
2x Xeon E5450 (3 GHz QuadCore)
24 GB RAM
6x 600 GB 3.5" 15k SAS (Seagate Cheetah 15k[6/7]) as RAID 5
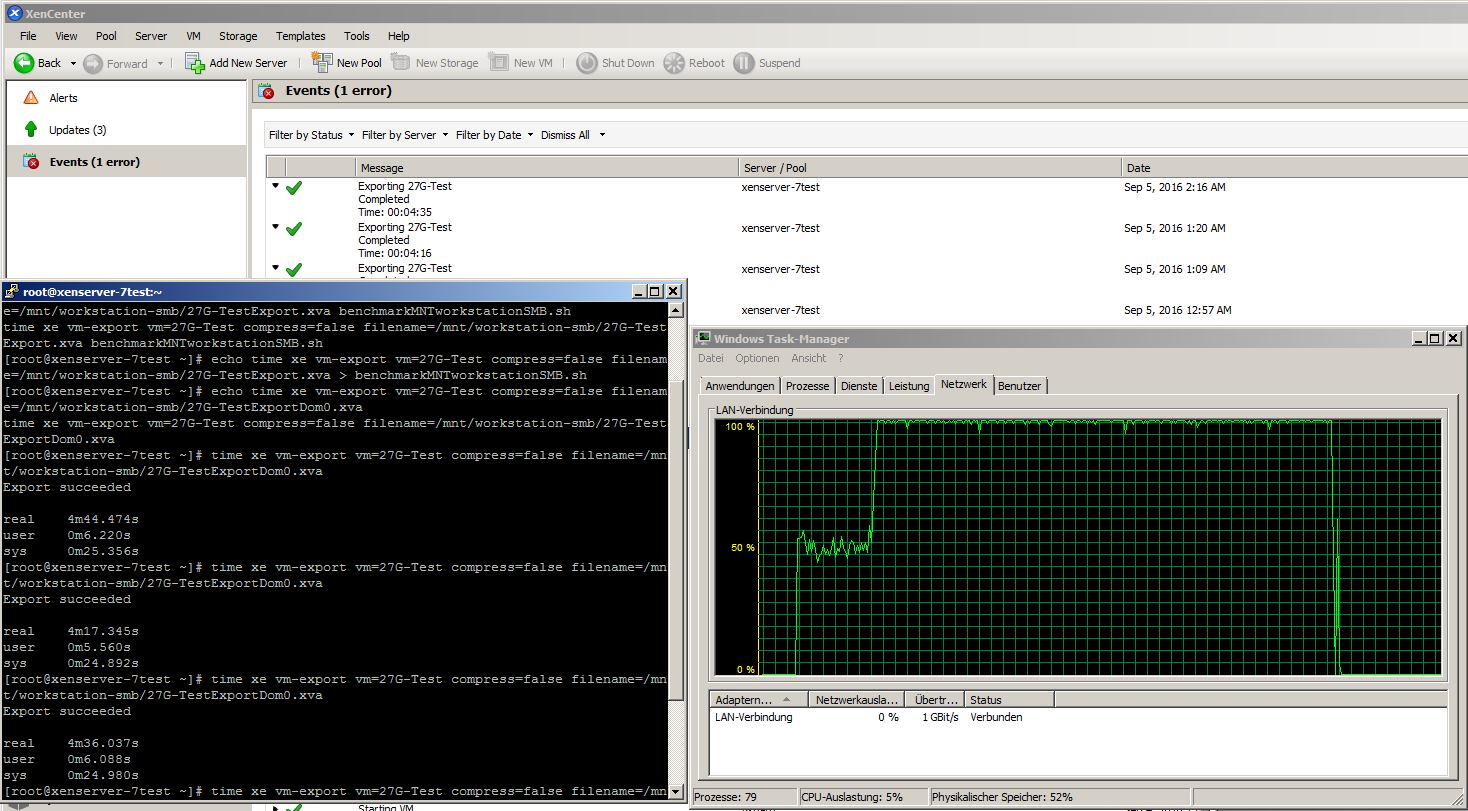
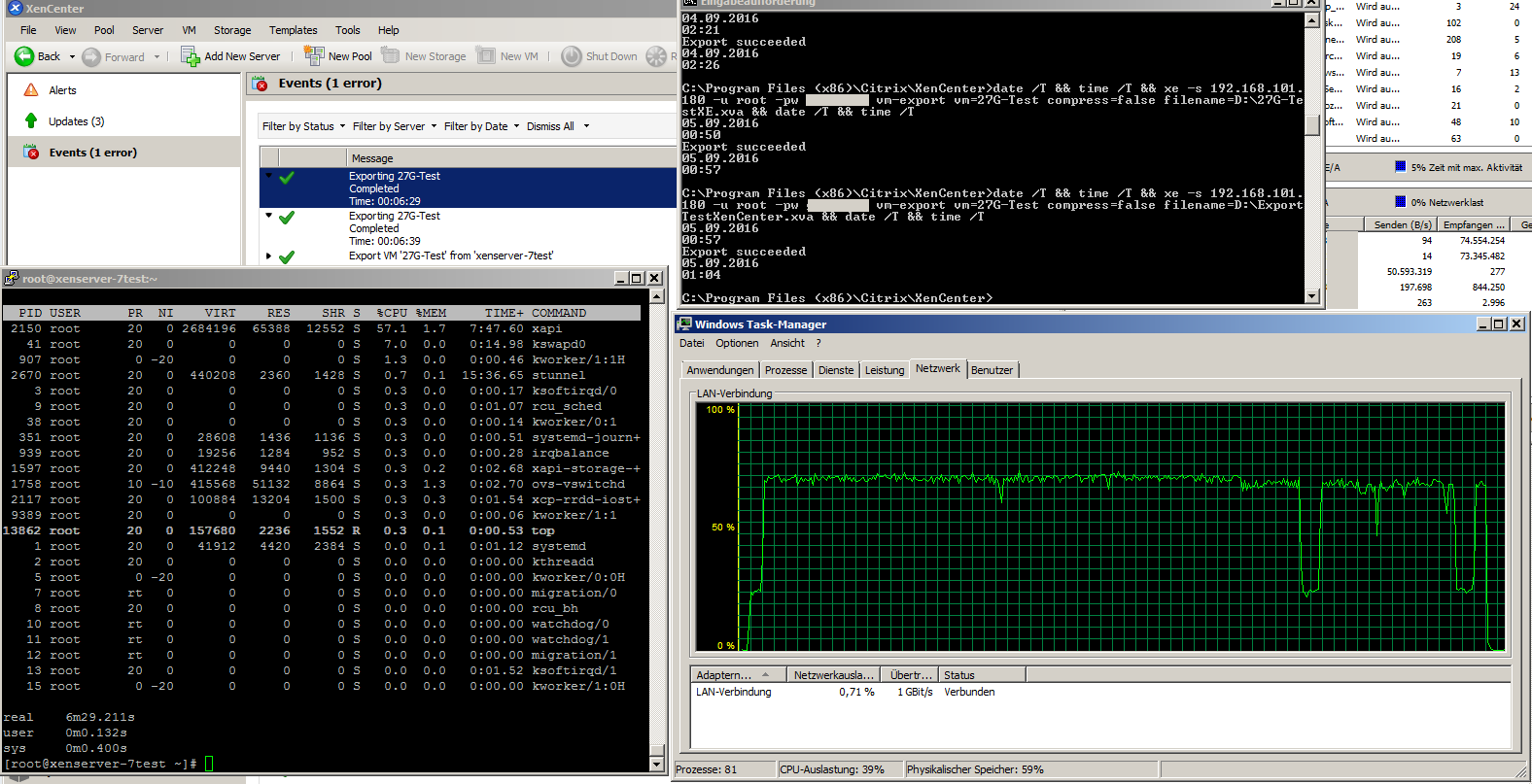
To decrease the total time to export (it'd take days if not), I parallelize the exports to 2 exports at once. That means I start with Exchange and iterate through the list of VMs - with the result, that while exporting Exchange, all other VMs are getting exported and the Exchange export is still running and script is waiting for it, to continue moving stuff to tape then.
I'm triggering the exports via xe.exe from XenCenter (currently tying Dundee Beta 2 v. 6.6.90.3063) by a small windows batch file.
The main part is just basics:
%XenServer% vm-export vm=%1 compress=false filename=%BackupPath2%%1.xva
Means, for speed-reasons, I disable compression - as the tapedrive does it itself and the Exchange-DB and other VMs probably won't compress that good anyways.
From time to time, I clean VMs by using "sdelete -z" to zero empty space.
What I could see:
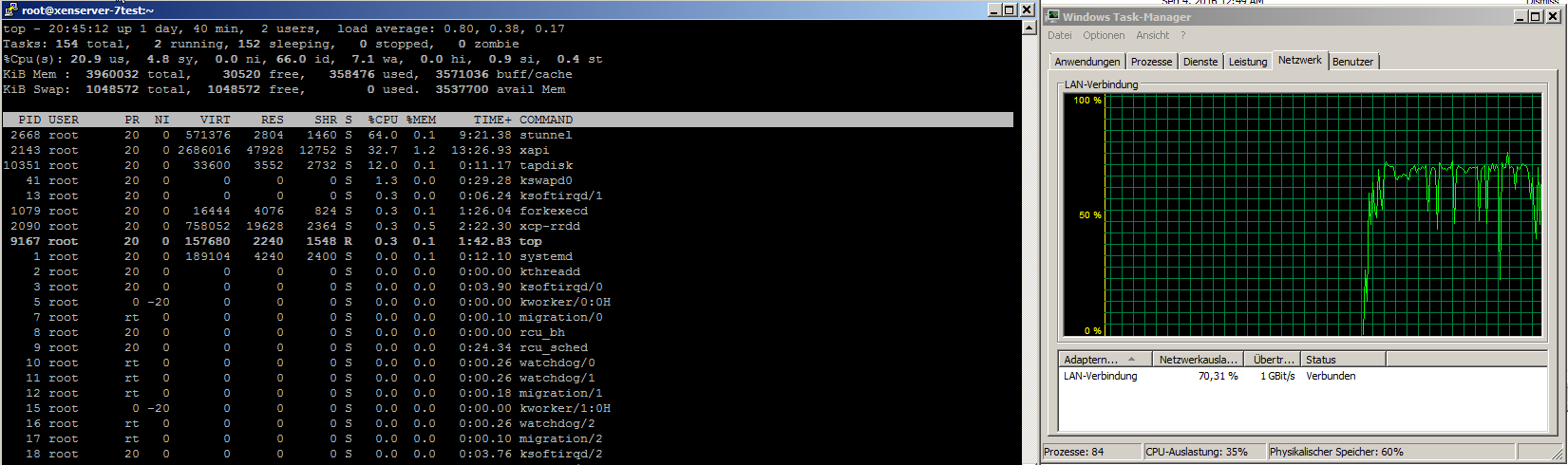
xe.exe consumes only core at the backupsystem, means everything is single-threadded - whyever.
xe.exe from Exchange export, is usually hitting it's one-core-max-usage, what seems to limit that.
Dom0 has a load average of, currently: 3.12, 3.04, 2.98
stunnel consumes most time by about 100-150% and xapi about 40-50%, another process, "fe" (whatever it is) takes ~10-12 and then some drops of performance for tapdisk/qemu-dm processes.
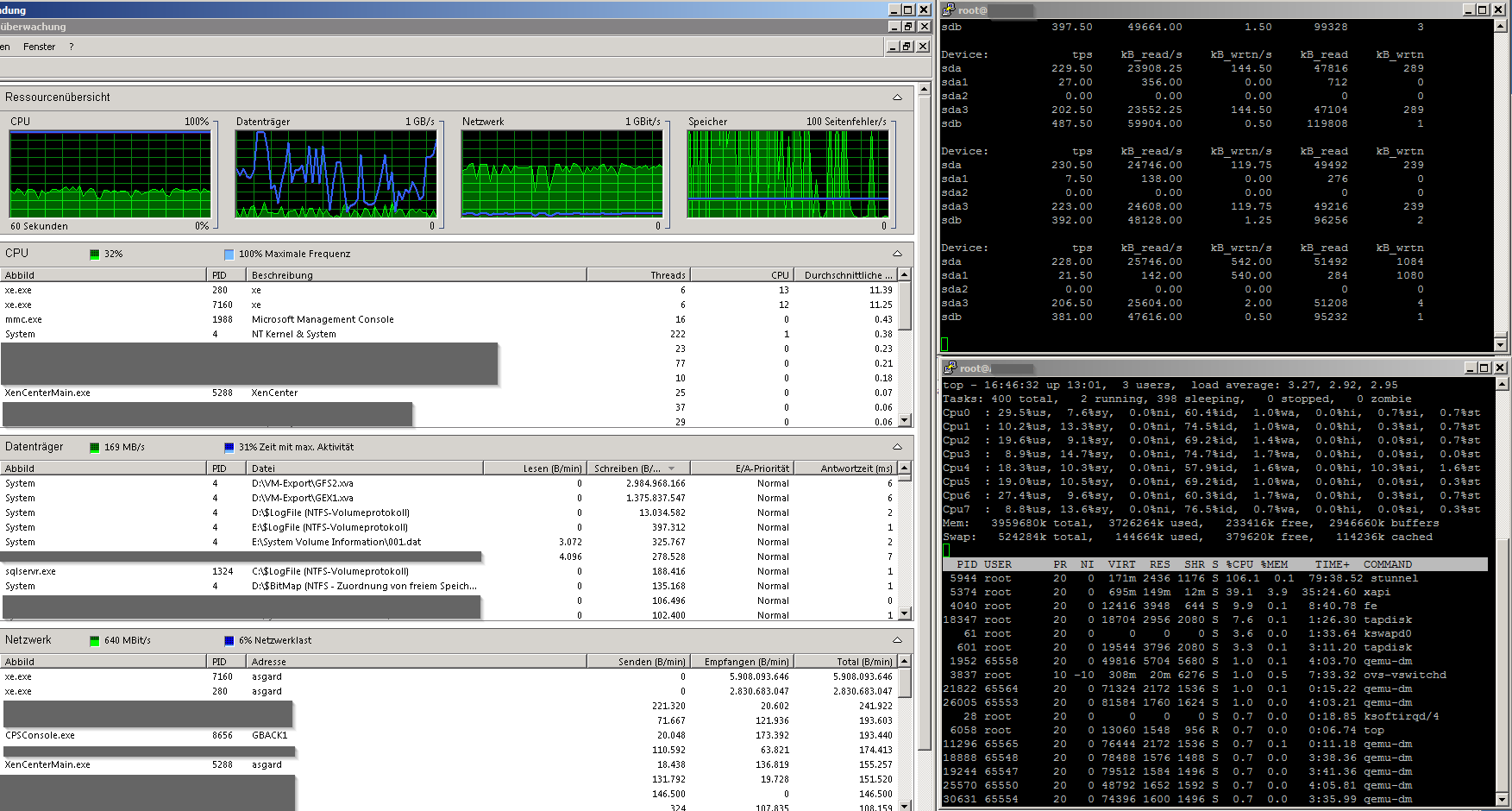
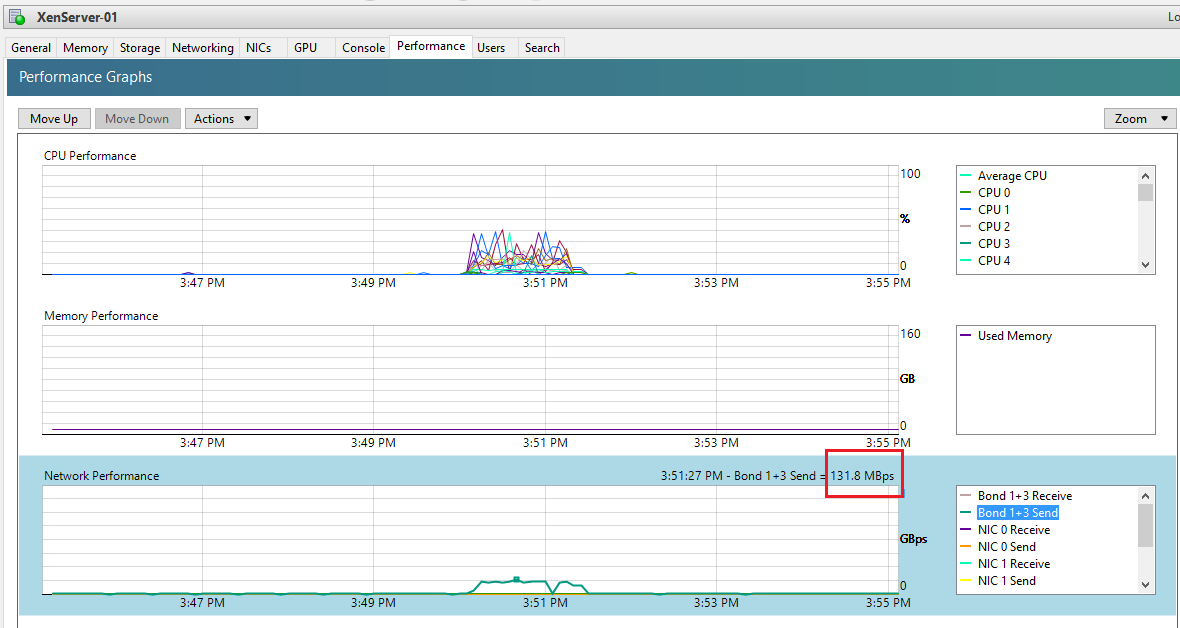
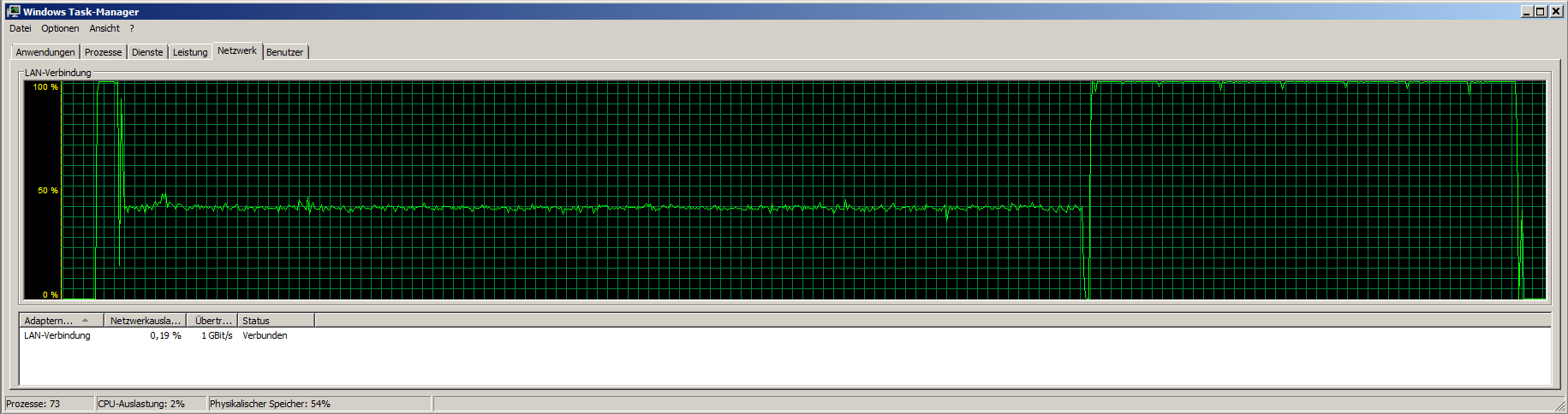
Measured by iostat, tps are mostly between 300 and 400, with peaks up to 1200+ and a read-speed of 20-40 MB/s with short peaks up to over 350 MBs.
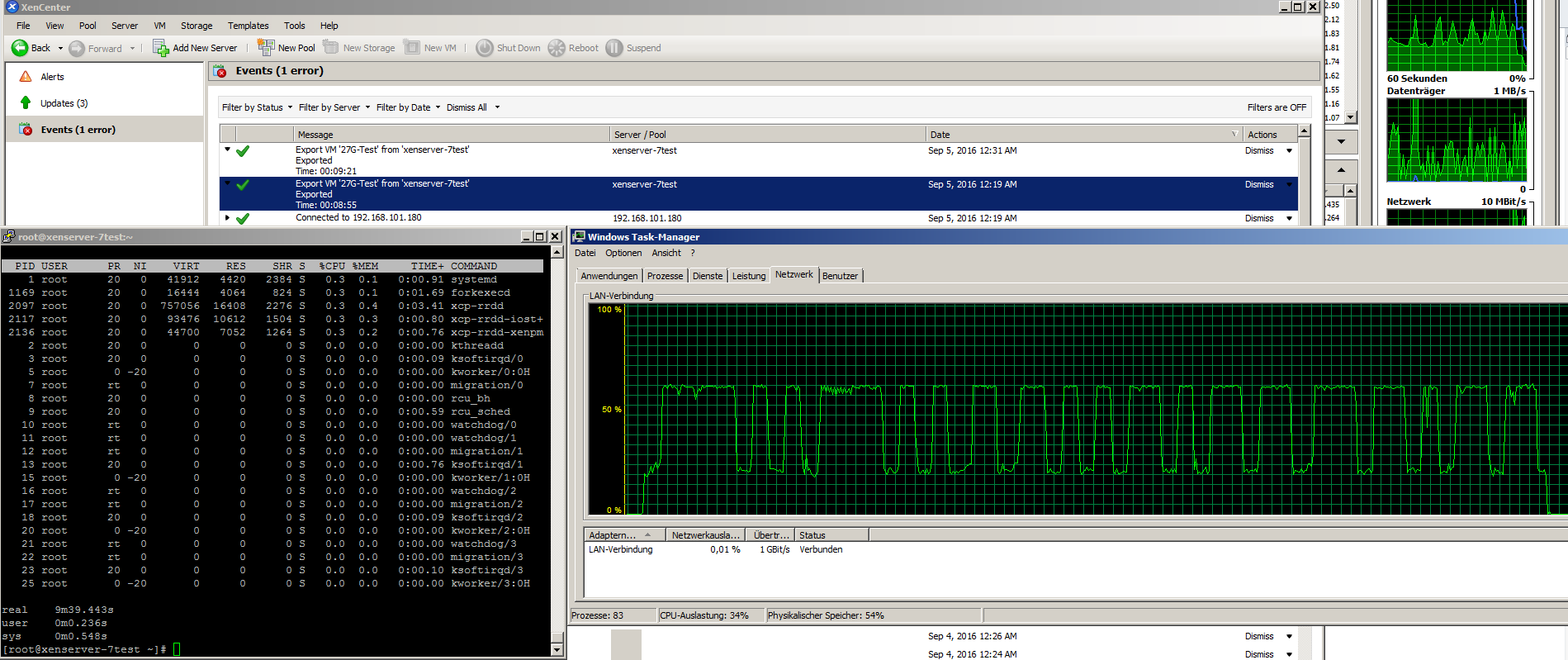
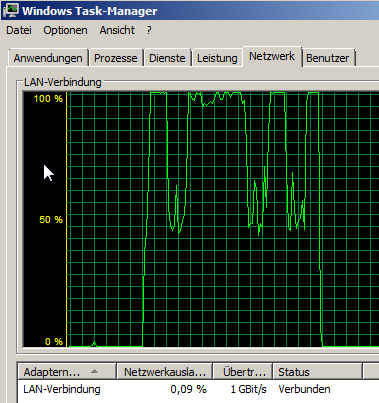
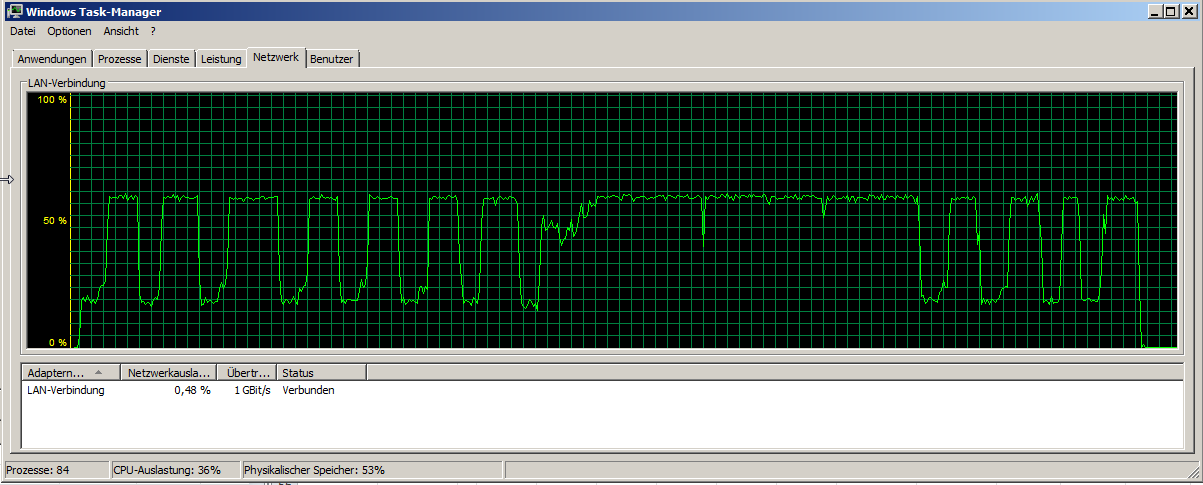
Load on the backupsystem is jumping around a bit:
from 200-800 mbit/s, disk at 20-100 MB/s and a total CPU-usage of about 33%.
CPU-usage is mostly constat around 30%.
Network currently holds 500-700 mbit/s, HDDs time of max. activity jumps between about 9 and 90%, very rarely hitting 100%.
Attached a screenshot while exporting (backupserver at the left).
The blue lines at "Datenträger" (Data disks) is the saturation of the RAID set, green is the amount of data transfered.
What we could see from the screenshot:
1. RAIDs are not constantly at their limits
2. Network is far away from limiting anything
That leaves, that there is some optimisation at the CPU-usage/process handling needed.
Probably some multi-tasking stuff for xe.exe, that splits the various steps needet to convert data from XenServer(API?) to a .xva file on the harddisk.
For an imagination of how many ppl. already tried to fix that or have been that much affected, that they tried fo find help at the forums, there is an over-the-years-growed thread:
https://discussions.citrix.com/topic/237200-vm-importexport-performance/
(So imagine how many ppl. just didn't post/only read but still are affected)
I'm willing to make more analyzes or giving needed details/doing export tests with a prepared VM or whatever you need, but please, please, please work on that, since it's a major bug for using and maintaining XenServer and by growing VMs and datastores, that problem won't decrease.
I hope you understand our (see the list of ppl. contributed to the thread) pain.
Regards
- Christof